
One question that always arises when we talk about shards is the sizing. For argument’s sake, we will focus on a use case with one index on a 5-node cluster and then find the shard sizing with multi-indices on the 5-node cluster in this article.
Single index setup
Let’s say that we have a 5-node cluster with one index that is made up of 10 primary shards and 2 replicas. This means that each shard has 2 replicas with the total number of shards as 30 for both primary and replicas. The figure below shows this configuration.
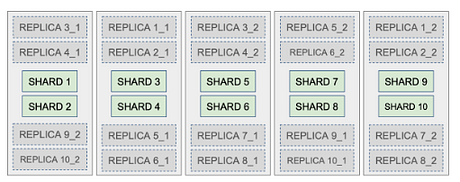
Let’s also assume that the primary shards consist of a few million documents occupying 300 GB worth of memory. We therefore create a 10-shard index with each shard allocated with about 50 Gb of memory. Elasticsearch distributes this 300 Gb data among 10 shards so, more or less, each shard gets 30 Gb worth of documents. We also have two replicas for each shard resulting in 20 replicas.
Replicas need setting up with the same memory as the main shard because they are copies of the shard. Thus, 20 replicas will consume 20 times 50 Gb, which equals 1000 Gb. Don’t forget adding up the memory allocated to the primary shards: 10 shards times 50 Gb = 500 Gb. In total, we need at least 1500 Gb (1.5 TB) for running this cluster with one index. The figure below provides these calculations.

As you can see from the calculations in the figure, for a single index with 10 shards and 20 replicas, we will need a cluster that’s commissioned close to 2000 Gb (2 Tb) in total. This cluster is made of individual nodes.
Remember, these nodes need additional memory for operational purposes including system indices, in-memory data structures, and other operations. Hence, it is always advisable to add additional memory aside from that which is allocated to the shard sizing. As we mentioned, we are building a 5-node cluster, so, perhaps, each nod kid e with 400 Gb would make up the cluster with 2000 Gb. This would suffice for the current use case.
Multiple indices setup
In our example, we assumed we only had one index to manage and, hence, tried calculating memory cost based on that lone index. This is rarely the case in the real world. Any number of indices can exist on the server, and at the very least, we need to provision servers with the intention of creating a handful of indices in the future. If we extrapolate the cost calculations for 5 indices with each index having 10 shards and 2 replicas per index, the figure below gives us an indication of our estate memory.

As you can gather, memory exponentially increases when we start to consider additional indices. In the earlier case of one index with 10 shards and 20 replicas (previous figure), we commissioned a 5-node cluster to cater to 2000 Gb of space requirements. In this new case with multiple indices (figure shown above), we may need a humongous cluster that would cater to about 10 Tb of space. We can deal with this in two ways: vertical scaling or horizontal scaling.
Vertical scaling
We can use the same cluster that serves the 2 Tb memory requirements and prop up the additional memory to cater to new memory requirements; for example, each server going up to 2 Tb (5 nodes with 2 Tb = 10 Tb). This is more of a vertical scaling activity. Although this is not an issue on a technical level, you may need to take the server down to get it upgraded.
Horizontal scaling
The alternate (and probably preferred recommendation) is to add additional nodes to the cluster. For example, we can add 20 more nodes to the server, making the total nodes equal to 25. We then have a newly formed cluster with 25 nodes, where each node has 400 Gb of memory that caters all together to 10 Tb of our memory requirements.
While there is no one-size-fits-all solution, having a forward-thinking strategy with a tried and tested approach works well for most organizations. Shard sizing is a tedious activity, and we need to exercise extreme caution and care to size it appropriately.
Because one of the major administrative requirements is to take backups of a few indices or the cluster as a whole from time to time. Elasticsearch provides a sleek mechanism for backing up and restoring — a snapshot.
These short articles are condensed excerpts taken from my book Elasticsearch in Action, Second Edition. The code is available in my GitHub repository.
