
Elasticsearch has a handful of advanced queries dedicated to serving a specialized function. For example, boosting the score for cafes serving chilled drinks at a specified location using distance_feature query — the subject of this article.
When searching for classic literature, we may want to add a clause to find the books that were published in 1813. Along with returning all the books that are literature classics, we can expect to find Pride and Prejudice (Jane Austen’s classic), but the idea is to show Pride and Prejudice at the top of the list because it was printed in 1813. Topping the list is nothing more than boosting the relevance score of the query results based on a particular clause; in this case, we specifically want the books published in 1813 to be given higher importance.
This sort of feature is available in Elasticsearch by using the distance_feature query. The query fetches the results and marks a few of them with a higher relevancy score if they are nearer to an origin date (1813 in this example).
The distance_feature query also provides similar support for locations. We can highlight the locations nearer a particular address boosted to the top of the list if we so desire. Say that we want to find all the restaurants serving fish and chips, but those topping the list should be near Borough Market by London Bridge. (Borough Market is a world-renowned thirteenth century artisan food market; see https://boroughmarket.org.uk.)
We can use the distance_feature query for such use cases, which works on finding the results nearer an origin location or date. The dates and locations are fields declared as date (we can declare it as date_nanos too) and geo_point data types respectively. The results that are closer to the given date or given location are rated higher in relevance scores. Let’s look at a couple of examples to understand the concept in detail.
Boosting score for nearby universities using geolocations
While searching for universities in the United Kingdom, we would like to give preference to universities that are closer to a place; say, all the universities within a 10 km radius of the Knightsbridge. We need to boost the scores for these matches.
To try out this scenario, let’s create a mapping for the university index with a location declared as a geo_point field. The following listing creates the mapping as well as the indexes for four universities: two in London and two elsewhere in the country.
# Create a mapping of universities index with bare minimum fields
PUT universities
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"location":{
"type": "geo_point"
}
}
}
}
# And index a few universities
PUT universities/_doc/1
{
"name":"London School of Economics (LSE)",
"location":[0.1165, 51.5144]
}
PUT universities/_doc/2
{
"name":"Imperial College London",
"location":[0.1749, 51.4988]
}
PUT universities/_doc/3
{
"name":"University of Oxford",
"location":[1.2544, 51.7548]
}
PUT universities/_doc/4
{
"name":"University of Cambridge",
"location":[0.1132, 52.2054]
}
Now that the index and data is prepped, let’s fetch universities, boosting the relevance scores so that those closer to London Bridge are at the top of the list. See the map of London in figure 12.12 with the approximate distances of these universities around said locations. We use the distance_feature query for this purpose, which matches the query criteria but boosts the relevance score based on the additional parameters provided in the query.
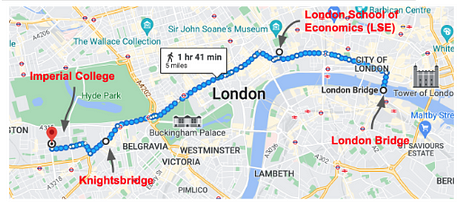
First, let’s write the query and then dig into it to learn the details. The following listing uses a distance_feature query within a bool query to fetch the universities.
GET universities/_search
{
"query": {
"distance_feature": {
"field": "location",
"origin": [-0.0860, 51.5048],
"pivot": "10 km"
}
}
}
The query, when exectued, searches for all the universities returning our two universities, London School of Economics and the Imperial College London. Additionally, if any of these universities are in the vicinity of 10 km around the origin (-0.0860, 51.5048 represents London Bridge in UK), they are scored higher than the others.
Let’s take a pause and see what’s the distance_feature query is made of. The distance_feature query expects these properties:
field— Thegeo_pointfield in the documentorigin— The focal point (in longitude and latitude) from which to measure the distancepivot— The distance from the focal point
In the above query, London School of Economics (LSE) university is closer to London Bridge than Imperial College; hence, LSE is returned at the top with a higher score.
We can also use the distance_feature query with dates too, topic of the next section.
Boosting the score using dates
In the last section, the distance_feature query helped us to search for universities, boosting the score for those that are nearer to a certain geolocation. There’s also a similar requirement that can be satisfied by the distance_feature query: boosting the score of the results if they are pivoted around a date.
Let’s say that we want to search for all the iPhone release dates, topping the list with those iPhones that were released within 30 days around December 1, 2020 (no particular reason, other than trying out the concept). We can write a similar query as we did in the last section, except the field attribute will be based on a date. Let’s first create an iphones mapping and index a few iPhones into our index. The query in the following listing does that.
PUT iphones
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"release_date":{
"type": "date",
"format": "dd-MM-yyyy"
}
}
}
}
# Indexing a few documents
PUT iphones/_doc/1
{
"name":"iPhone",
"release_date":"29-06-2007"
}
PUT iphones/_doc/2
{
"name":"iPhone 12",
"release_date":"23-10-2020"
}
PUT iphones/_doc/3
{
"name":"iPhone 13",
"release_date":"24-09-2021"
}
PUT iphones/_doc/4
{
"name":"iPhone 12 Mini",
"release_date":"13-11-2020"
}
Now that we have an index with a bunch of iPhones in it, let’s develop a query to satisfy our requirement: we’ll fetch all iPhones but prioritize the ones released 30 days around the first of December, 2020. The query in the next listing does this.
GET iphones/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "12"
}
}
],
"should": [
{
"distance_feature": {
"field": "release_date",
"origin": "1-12-2020",
"pivot": "30 d"
}
}
]
}
}
}
In the above query, we wrap a distance_feature in a bool query with a must and a should clause (we learned about the bool query in our earlier articles). The must clause searches for all the documents with 12 in the name field and returns iPhone 12 and iPhone 12 mini documents from our index. Our requirement is to prioritize the phones released 30 days around the first of December (so, potentially, all phones released between November to December, 2020).
To satisfy this requirement, the should clause uses the distance_feature query to enhance the scores for the matching documents closest to the pivoted date mentioned. The query fetches all the documents from the iphones index. Any iPhone released 30 days before or after December 1, 2020 (origin) is returned with a higher relevance score.
Remember, all the matches the should clause returns will add to the overall score. Hence, you should see iPhone 12 Mini topping the list because the release date (“release_date”:”13–11–2020″) of this iPhone is closer to the pivoted date (“origin”:”01–12–2020″ 30 days). The results of the query are presented in the following snippet for completeness.
"hits" : [
{
"_index" : "iphones",
"_id" : "4",
"_score" : 1.1876879,
"_source" : {
"name" : "iPhone 12 Mini",
"release_date" : "13-11-2020"
}
},
{
"_index" : "iphones",
"_id" : "2",
"_score" : 1.1217185,
"_source" : {
"name" : "iPhone 12",
"release_date" : "23-10-2020"
}
}
]
As you can see, the iPhone 12 Mini scored higher than the iPhone 12 because it was released just 17 days prior to our pivot date, while the iPhone 12 was released a bit earlier than that (almost 5 weeks prior).
That’s pretty much it; do follow me more and of course, give me a clap 🙂
These short articles are condensed excerpts taken from my book Elasticsearch in Action, Second Edition. The code is available in my GitHub repository.
