
This is part 3/n series on Mapping:
- 1: Overview of Mapping
- 2. Dynamic Mapping
- 3. Explicit Mapping
- 4. Core data types
- 5. Advanced data types
Elasticsearch is intelligent to derive the mapping information based on our documents, however, there is a chance things could end up with an incorrect schema definition. Fortunately, Elasticsearch provides the ways and means for us, the user, to dictate the mapping definitions the way we want to in the form of indexing and mapping APIs.
The following lists two possible ways of creating (or updating) a schema explicitly.
- Indexing APIs: We can create a schema definition at the time of index creation using the
create indexAPI (not themappingAPI, note) for this purpose. Thecreate indexAPI expects a request consisting of the required schema definition in the form of a JSON document. This way, a new index and its mapping definitions are all created in one go. - Mapping APIs: As our data model matures, at times there will be a need to update the schema definition with new attributes. Elasticsearch provides a
_mappingendpoint to carry out this action, allowing us to add the additional fields and their data types. We can use this API to add schema to a freshly created index for the first time too.
As an example, look at the figure below, which demonstrates using both APIs to create a movies index.
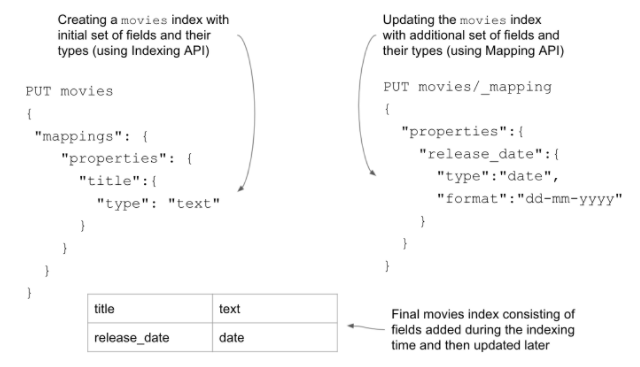
Mapping using the indexing API
Creating a mapping definition at the time of index creation is relatively straightforward. We simply issue a PUT command following with the index name and pass the mappings object with all the required fields and their details as the body of the request. The figure shown below explains the constituents visually.
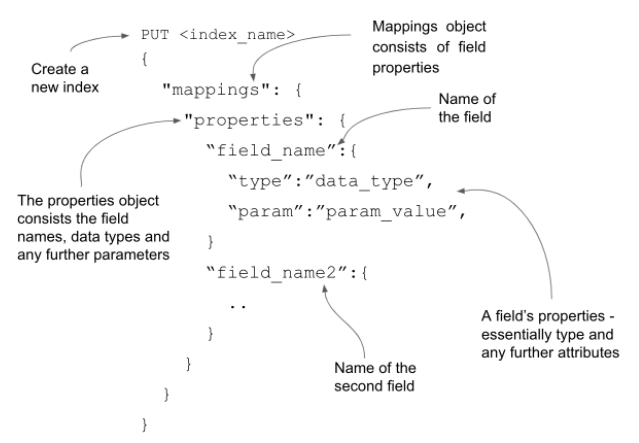
Let’s develop a mapping schema for an employee model — with the employee information being modelled with a bunch of fields such as name, age, email and address.
We index the document consisting of these fields into an employees index by invoking the mapping API over an HTTP PUT action. The request body is encapsulated with properties for our fields as the listing shown below.
# Creating an employees schema upfront
PUT employees
{
"mappings":{
"properties": {
"name":{"type": "text"},
"age":{"type": "integer"},
"mmail":{"type": "keyword"},
"address":{
"properties":{
"street":{"type":"text"},
"country":{ "type":"text" }
}
}
}
}
}
Once the script is ready, execute this command with Kibana’s DevTools. You should receive a successful response indicating that the index was created. In this example, we dictated the types to Elasticsearch; now we are in control of the schema.
Did you notice the address field in the listing? It is an object type, consisting of additional fields, street and country. One important thing to note is that the type of the address field has not been mentioned as an object type, although we said it was an object that encapsulates other data fields. The reason for this is that the object data type is deduced by Elasticsearch for any inner objects by default. Also, the sub-field properties object wrapped up in the address help define further attributes of the inner object.
Now that we have our employees index in production, say we want to extend the model to have a few more attributes such as department, phone number, and others. To cater to this requirement, we need to add these additional fields using the _mapping API on a live index.
Updating schema using the mapping API
As our project matures, there will be undoubtedly changes to the data model too. Going with our employee document, we may want to add a couple of attributes like joining_date and phone_number shown in the following code snippet.
# Additional data to the existing Employee document
{
"name":"John Smith",
"joining_date":"01-05-2021",
"phone_number":"01234567899"
...
}
The joining date is a date type as we want to do date-related operations, such as sorting employees by joining date. The phone number is expected to be stored as-is, so it fits the keyword data type. To amend the existing employees’ schema definition with these additional fields, we invoke a _mapping endpoint on the existing index, declaring the new fields in the request object as shown in the listing below.
# Updating the existing index with additional fields
PUT employees/_mapping
{
"properties":{
"joining_date":{
"type":"date",
"format":"dd-mm-yyyy"
},
"phone_number":{
"type":"keyword"
}
}
}
If you look at the request body closely, the properties object is defined at the root level as opposed to the earlier method of creating a schema using the indexing API where the properties object was wrapped in the root-level mapping object.
Updating an empty index
We can use the same principle of updating the schema on an empty index too. An empty index is an index created without any schema mapping — for example, executing the PUT books the command creates an empty books index with no schema associated with it.
Similar to the mechanism to update the index by calling the _mapping endpoint with the required schema definition, we can use the same approach for the empty index too. The following code snippet updates the schema on the departments index with a couple of fields:
# Adding the mapping schema to an empty index
PUT departments/_mapping
{
"properties":{
"name":{
"type":"text"
}
}
}
We’ve seen the additive case of updating the schema with additional fields. But what if we want to change the data types of the existing fields?
Modifying the existing fields is not allowed
Once an index is live (the index was created with some data fields and is operational), any modifications of the existing fields on the live index are prohibited. For example, if a field was defined as a keyword data type and indexed, it cannot be changed to a different data type (say, from keyword to a text data type). There is a good reason for this though.
Data is indexed using the existing schema definitions and, hence, stored in the index. The searching on that field data fails if the data type has been modified, which leads to an erroneous search experience. To avoid search failures, Elasticsearch does not allow us to modify existing fields.
Well, you may ask, what would be the alternative? Business requirements change as do the technical requirements. How can we fix data types (maybe, we have incorrectly created them in the first place) on a live index? Re-indexing is our friend.
Reindexing data
This is where we use a re-indexing technique. Re-indexing operations source the data from the original index to a new index with updated schema definitions. The idea is that we
- Create a new index with the updated schema definitions.
- Copy the data from the old index into the new index using re-indexing APIs. The new index with the new schema will be ready to use once the re-indexing is complete. The index is open for both read and writes operations.
- Once the new index is ready, our application switches over to the new index.
- We shelf the old index once we confirm the new index works as expected.
Re-indexing is a powerful operation, which is discussed in detail in Chapter 5: Working with Documents of the book, but let me give you a glimpse of how the API works. Say we wish to migrate data from an existing (source) index to a target (dest) index, we issue a reindexing call, as shown in the code listing 4.7 below:
# Migrating data to a new index with new schema
POST _reindex
{
“source”: {“index”: “orders”},
“dest”: {“index”: “orders_new”}
}
The new index orders_new may have been created with the changes to the schema and then the data from the old index (orders) is migrated to this newly created index with updated declarations.
Aliases play an important role in migration
If your application is rigidly tied up with an existing index, moving to the new index may require a code or configuration change. For example, in the above case, all your queries pointing to the orders index will now be executed against the newly createdorders_new index — and this may require a code change.
The ideal way to avoid such situations is to use aliases. Aliases are the alternate names given to indices. Aliasing helps us switch between indices seamlessly with zero downtime. We will look at aliases in Chapter 6: Indexing Operations of the book which deals with indexing operations in detail.
Type coercion
Sometimes the data may have incorrect types when indexing the documents — an integer-defined field may be indexed with a string value. Elasticsearch tries to convert such inconsistent types, thus avoiding indexing issues. This is a process known as type coercion
Take an example: a rating field of type float may have received a value enclosed as a string: “rating”: “4.9” instead of “rating”:4.9. Elasticsearch is forgiving when it encounters mismatched values for data types. It goes ahead with indexing the document by extracting the value and storing it in the original data type.
In this article, we looked at how we can take control and create our mapping schema for the data models we own.
In the next article, we look at data types in detail — stay tuned!
These short articles are condensed excerpts taken from my book Elasticsearch in Action, Second Edition. The code is available in my GitHub repository.
