
This is part 2/n series on Mapping:
- 1: Overview of Mapping
- 2. Dynamic Mapping
- 3. Explicit Mapping
- 4. Core data types
- 5. Advanced data types
When we try to index a document for the first time, both the mapping and the index will be created automatically. The engine wouldn’t give you trouble for not providing the schema upfront. Elasticsearch is more forgiving on that count. We can index a document without having to let the engine know anything about the field’s data types. Consider a movie document consisting of a few fields, shown below.
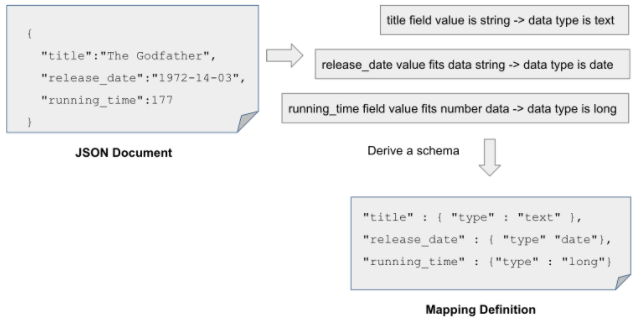
Reading the fields and the values in this document, Elasticsearch infers the data types automatically. For example:
- The
titlefield value is a string, so it maps the field to atextdata type; - The
release_datefield value is a string, but the value matches an ISO 8601 date format so it is mapped to adatetype. - Also, the
running_timefield is a number, so Elasticsearch maps it to alongdata type.
We are not explicitly creating the mapping but letting Elasticsearch derive the schema on the fly — this type of mapping is termed dynamic mapping. This feature is quite handy during application development and testing.
How did Elasticsearch know the data type of the ratings filed is a float type? For that matter, how does Elasticsearch deduce the types of those fields? Let’s understand the mechanism behind deducing the types.
How Elasticsearch derives the types
Elasticsearch analyzes the values and guesses the equivalent data type based on the values. When the incoming JSON object is parsed, the rating value of 4.9, for example, resembles a floating-point integer in programming language lingo. This “guesswork” is pretty straightforward; hence, Elasticsearch stamps the rating field as a float field.
While deducing the number type might be easy, how about the type of the release_year field? The release_year field’s value is compared and matched to one of the two default date formats: yyyy/MM/dd or yyyy-MM-dd. If it matches, the type is assigned as a date data type.
Elasticsearch can deduce a field as a date type if the values in the JSON document are provided in either of the format: yyyy-MM-dd or yyyy/MM/dd although the latter isn’t an ISO date format. However, this flexibility is available for dynamic mapping cases only. That is, should you declare the field as a date type explicitly (explicit mapping), unless you provide a custom format, by default the field would be adhering to strict_date_optional_time format. The strict_date_optional_time conforms to an ISO date format, i.e.,yyyy-MM-dd or yyyy-MM-ddTHH:mm:ss. That is, you cannot provide the date in yyyy/MM/dd format after you’ve declared your field’s type as a date.
Your data — your schema
While Elasticsearch is clever enough to derive the mapping information based on our documents, which allows us not to worry about schemas, at times it could go badly and we would end up with an incorrect schema definition.
As we tend to have a good understanding of our domain and know the data models pretty much inside and out, my advice is not to let Elasticsearch create our schemas, especially in production environments. Instead, aim to create schemas upfront, most likely creating a mapping strategy across the organization using mapping templates (we will work through some mapping templates later).
Although the dynamic mapping feature is attractive, it does carry limitations.
Limitations of dynamic mapping
While the dynamic mapping feature is attractive, there are some limitations for letting Elasticsearch derive the document schema. Elasticsearch could misinterpret the document field values and derive an incorrect mapping that voids the fields eligibility for appropriate search, sort and aggregation capabilities.
Consider the release_year field in our movie document. If our document has a value for release_year in a different format (say, ddMMyyyy or dd/MM/yyyy ), the dynamic mapping rule breaks down. Elasticsearch will consider that value as a text field rather than a date field.
Similarly, if you try indexing another document by setting the rating field value to 4 (our intention is to provide the ratings as decimal points), Elasticsearch stamps that field as a long data type, derived it by looking at the field’s value (4) instead of a floating-point. Elasticsearch fell short in deriving the appropriate type.
In both cases, we have a schema with incorrect data types. Having incorrect types will cause potential problems in an application, making the fields ineligible for sorting, filtering, and aggregations on data. This is the best that Elasticsearch can do when we use its dynamic mapping feature.
How does Elasticsearch derive incorrect types?
Let’s find out how Elasticsearch deduces data types incorrectly and thus leads to inaccurate and erroneous mapping rules.
Say our intention was to provide a field with numeric data but wrapped up as a string (for example “3.14“). Unfortunately, Elasticsearch treats such data incorrectly, as, in this example, it would expect the type to be text, not float or double datatype.
Have a look at the example of a student document given below.

Let’s modify our student document and add another field: student’s age field, which though sounds like a number, we index it as a text field by wrapping the value within quotes, as shown here:
### Adding age field with text values to the student document PUT students_temp/_doc/1
{
"name":"John",
"age":"12"
}
PUT students_temp/_doc/2
{
"name":"William",
"age":"14"
}
As the age field’s value is enclosed in quotes, Elasticsearch will treat it as a text field (though it has numbers). Once we index two documents, we can write a search query to sort the students in ascending or descending order, based on their age. This is shown below:

sort operation on a text field results in an errorThe response indicates the operation is not allowed. As the age field of a student document is indexed as a text field (by default, any string field is mapped to a text field during the dynamic mapping process), Elasticsearch cannot use that field in sorting operations. Sorting functionality is not available on text fields.
Fixing the sorting using keyword types
Not all is lost, fortunately, Elasticsearch creates any field as a multi-field with the keyword as the second data type by default. Going with this default feature, the age field is indeed tagged as a multi-field, thus creating age.keyword a second data type with keyword being the data type. To sort the students, all we need to do is change the field name from age to age.keyword, as demonstrated in the listing given below.
# The sort queryGET students_temp/_search
{
"sort": [
{
"age.keyword": {
"order": "asc"
}
}
]
}
This query will result in all students in ascending order of age. The query will execute successfully because the age.keyword is a keyword type field where we can apply a sorting function. We are sorting on the second data type ( age.keyword ) which was created by Elasticsearch by default.
The age.keyword in the example above is the default name provided by Elasticsearch during dynamic mapping. We have full control of creating the fields, their names and types when defining the mapping schemas implicitly. So, you can name it as you want, for example, age_raw or something of your choice!
Do note that text fields are expected to undergo text analysis. Treating a field as a text type instead of a keyword will unnecessarily affect the engine as the data gets analyzed and broken down into tokens.
Deriving incorrect date formats
There’s also another potential problem with dynamic mapping: date formats may be derived incorrectly if not provided in Elasticsearch’s default date format (yyyy-MM-dd or yyyy/MM/dd). The date is considered as a text type if we post the date in formats like UK’s dd-MM-yyyy or US’s MM-dd-yyyy formats. We cannot perform date math on the fields associated with non-date data types. Such fields are ineligible for sorting, filtering, and aggregations too.
There is no date type in JSON, so it’s up to the consuming applications to decode the value and deduce it to be a date (or not). Elasticsearch checks the format of the string and deduces the field’s type to be a date type if the value follows a date pattern.
The takeaway when working with dynamic mapping features of Elasticsearch is that there is a scope for erroneous mapping deduced by Elasticsearch at times. Preparing our schema based on the field values may not fit the bill sometimes. Hence, the general advice is to develop the schema as per your data model requirements rather than falling at the mercy of the engine.
To overcome those limitations, we can choose another alternative path: explicit mapping, where we define our schema and create it before the indexing process kicks in. We look at the explicit mapping in our next instalment.
These short articles are condensed excerpts taken from my book Elasticsearch in Action, Second Edition. The code is available in my GitHub repository.
